Understanding Bayesian Thinking for Industrial Applications
Learn how Bayesian thinking can enhance decision-making in industrial applications. This article lay the foundation of bayesion modelling with Pymc and their practical use cases.
A company has recently installed a new, expensive machine. A critical question arises: How long will it last before failure?. The lead engineer, drawing on experience with previous models, estimates a lifespan of approximately 10 years. However, only 3 months of real-world test data are available for this specific unit, and a major warranty and service contract decision must be made immediately.
This scenario exemplifies a common challenge in industrial applications: making informed decisions with limited data. Bayesian thinking offers a powerful framework to address such problems by combining prior knowledge with observed data to update our beliefs about uncertain parameters.
In this article, we will explore the fundamentals of Bayesian thinking and how it can be applied to industrial scenarios like the one described above. We will cover key concepts such as prior distributions, likelihood functions, and posterior distributions, and demonstrate how to implement Bayesian models using Python’s PyMC library.
To immediately dive into the code and reproduce the models discussed in this article, you can use our accompanying resources:
Traditional (Frequentist) statistics relies on large datasets the “long run” to produce confident conclusions, a limitation in industrial contexts where data are often sparse. New products, machines, or processes typically generate only small samples, while valuable expert knowledge such as an engineer’s lifespan estimate is excluded from conventional models.
Bayesian inference overcomes these issues by combining prior knowledge with new data, enabling faster and more informed decisions when information is limited. This integration of expertise and evidence defines Bayesian thinking.
The process of updating our beliefs is formalized by Bayes’ Theorem. \[
P(\theta \mid D) = \frac{P(D \mid \theta) P(\theta)}{P(D)}
\]
While the formula looks mathematical, its components represent a beautifully intuitive learning cycle.
Let us break down how this relates to our machine failure problem; where \(\theta\) is the machine’s expected failure rate, and \(D\) is the 3 months of test data.
Prior, Likelihood, and Posterior
Prior\(P(\theta)\) represents the initial belief before observing any data. It incorporates domain expertise and historical knowledge. For instance, historical records may indicate that similar machines have an average lifespan of approximately ten years, implying a low failure rate. This prior belief defines the starting point for 𝜃 \(\theta\).
Likelihood\(P(D \mid \theta)\) quantifies the compatibility between the observed data and a given parameter value. It expresses the probability of observing the test outcomes for different possible failure rates. In this context, the likelihood measures how probable it is to observe zero failures within three months if the true average lifespan were, for example, five or fifteen years.
Posterior\(P(\theta \mid D)\) represents the updated belief after incorporating the observed data. It integrates prior knowledge with the evidence provided by the likelihood. In the machine-failure example, the posterior distribution expresses the updated estimate of expected lifespan after combining historical information (e.g., the ten-year prior) with the three months of failure-free operational data.
PyMC: The Probabilistic Programming Engine
Understanding the relationship \(\mathrm{Posterior} \propto \mathrm{Likelihood} \times \mathrm{Prior}\) is the conceptual heart of Bayesian analysis. However, calculating the actual posterior distribution, \(P(\theta \mid D)\), often involves complex, multi-dimensional integration that is impossible to solve analytically for real-world industrial problems. This challenge is addressed through Probabilistic Programming Languages (PPLs) such as PyMC.
PyMC is an open-source Python library for constructing and fitting Bayesian statistical models using advanced computational algorithms, including Markov Chain Monte Carlo (MCMC) and variational inference. It is one of several modern PPLs available in Python, alongside Pyro and TensorFlow Probability (TFP). This tutorial focuses on PyMC due to its clarity, community support, and extensive documentation.
Case study: A/B Testing with Small Samples
To shift from theory to practical implementation, we will apply the Bayesian building blocks Prior, Likelihood, and Posterior to a concrete industrial problem common in tech and e-commerce: A/B Testing
Suppose you are a data scientist at an e-commerce company. The marketing team just launched a new website feature and wants to know:
What’s the true conversion rate?
Is it better than the old version (which historically has an 8% conversion rate)?
How much should we trust this estimate with limited data?
During the first few days of the feature launch, the company has observed 200 visitors with only 15 conversion.
Library Imports
Import the required Python libraries for Bayesian modeling:
NumPy for numerical computations
Pandas for data manipulation
PyMC for Bayesian statistical modeling
Matplotlib, arviz and altair for visualization
Show the code
#import librariesimport warningswarnings.filterwarnings("ignore", category=UserWarning)import pymc as pmimport arviz as azimport pandas as pdimport numpy as npfrom IPython.display import clear_outputfrom great_tables import GTimport matplotlib.pyplot as pltaz.style.use("arviz-white")from cycler import cyclercolors=['#107591','#f69a48','#00c0bf', '#fdcd49',"#cf166e", "#7035b7", "#212121","#757575", "#E0E0E0","#FAFAFA"]plt.rcParams.update({"figure.dpi": 100,"axes.labelsize": 12,"axes.titlesize": 12,"figure.titlesize": 12,"font.size": 12,"legend.fontsize": 12,"xtick.labelsize": 12,"ytick.labelsize": 12,"axes.linewidth" : 0.5,"lines.linewidth" : 1.,"legend.frameon" :False,'axes.prop_cycle': cycler(color=colors)})import altair altair.themes.enable('carbonwhite')import altair as altalt.data_transformers.enable('default', max_rows=None)clear_output()
Define key variables and parameters
Show the code
# For reproducibilitynp.random.seed(42)# A/B Test Parametersvisitors =200conversions =15observed_conversion_rate = conversions / visitorshistorical_baseline =0.08
Define Prior, likelihood, and Posterior in PyMC
To model this problem in PyMC, one must first define the Prior and Likelihood distributions
Prior: Since the conversion rate \(\theta\), can only range between 0 and 1. The Beta distribution is ideal for modeling parameters that are bounded between 0 and 1, such as probabilities or rates.
The Beta distribution is controlled by two parameters, \(\alpha\) and \(\beta\). hese parameters are set to formally encode the prior knowledge: the historical 8% conversion rate. The mean of a \(\mathrm{Beta}(\alpha,\beta)\) distribution is \(\frac{\alpha}{ \alpha + \beta}\). Since the historical rate is 8% (or 0.08), we need to choose \(\alpha\) and \(\beta\) such that: \[
\frac{\alpha}{ \alpha + \beta} = 0.08
\]
To determine the strength of this belief, a number that represents the effective sample size (ESS) of the historical knowledge is chosen. Choosing a hypothetical ESS of 100 trials, we can solve for \(\alpha\) and \(\beta\): - ESS \(= \alpha + \beta = 100\) - \(\alpha\) (hypothetical successes) \(=100×0.08=8\) - \(\beta\) (hypothetical failures) \(=100−8=92\)
Likelihood the Likelihood is determined by the process that generated the data. Since there is a fixed number of trials (N=200 visitors) and the number of successes (k=15 conversions) is counted, this is a Binomial distribution.
Show the code
with pm.Model() as conversion_model:# Prior distribution based on historical performance conversion_rate = pm.Beta("conversion_rate", alpha=8, beta=92)# Likelihood function likelihood = pm.Binomial("observations", n=visitors, p=conversion_rate, observed=conversions)# Sample from posterior distribution trace = pm.sample(2000, tune=1000, chains=4, random_seed=42, return_inferencedata=True)clear_output()
This small block of code above defines and runs our entire Bayesian analysis. For those seeing PyMC for the first time, here is what each section is doing:
with pm.Model() as model: This block acts as a container for all the random variables and data in our model. Everything inside this context belongs to the conversion_model
conversion_rate = pm.Beta(...): We are telling PyMC that the true conversion_rate is a random variable, and our initial belief is described by the Beta(8,92) distribution.
likelihood = pm.Binomial(...): This defines the process that generated our observed data. We link the conversion_rate parameter to the actual observed data (n=visitors, observed=conversions) using the appropriate Binomial distribution.
pm.sample(...): This is where the magic happens! The pm.sample function runs the MCMC sampler (the computational engine) to combine the Prior and the Likelihood, effectively calculating the Posterior distribution. We ask the sampler to draw 2000 samples after a 1000-sample tuning period, running 4 independent chains to ensure reliable results.
Model diagnostics
Running pm.sample() generates the raw output, but the job isn’t done yet. Before we trust the results, we must perform Model Diagnostics to ensure our computational engine (the MCMC sampler) has worked correctly. The single most important diagnostic check is confirming Convergence.
Model Convergencevergence
In Bayesian inference, Markov Chain Monte Carlo (MCMC) methods are employed to sample from the complex posterior distribution. These samples are relied upon to accurately estimate quantities like the mean conversion rate or its credible interval.
Convergence is the guarantee that the MCMC chains have explored the entire distribution and are now producing samples that truly represent the target Posterior distribution, and are not just stuck in a starting location.
Analogy: Imagine trying to understand the shape of a deep, misty valley (the posterior). If your chains haven’t converged, they might be stuck high up on a ridge, missing the true, deep center. Diagnostics are the tools we use to confirm the chains have found and are walking across the bottom of the true valley.
PyMC uses the supporting library ArviZ for standardizing and analyzing the results, which provides the following diagnostics and plots
Trace Plots: Visual inspection of parameter samples across iterations.
Good trace plots look like fuzzy caterpillars with no trends or jumps.
R-hat (Gelman-Rubin Statistic): Measures how well multiple chains agree.
R-hat ≈ 1 means convergence.
R-hat > 1.01 suggests problems.
Effective Sample Size (ESS): Indicates how many independent samples you effectively have.
Low ESS means poor mixing or autocorrelation. Good ESS is typically > 200 per parameter.
The most efficient way to check convergence numerically is using the ArviZ summary function, specifically asking for the diagnostics az.summary(trace, kind="diagnostics"). Alternatively, az.plot_trace(trace) can be used to get a visual sense of convergence.
This table immediately indicates that the model is reliable and ready for analysis
(R_hat = 1.0,Goal Achieved): Since R_hat is exactly 1.0, this confirms that the four independent MCMC chains have fully converged and agree on the shape of the posterior distribution. The model is reliable.
ESS bulk and ESS tail (3966.0 and 5559.0, Goal Achieved): Both effective sample sizes are significantly greater than the ≥400 minimum threshold. This means there are plenty of high-quality, effectively independent samples to accurately estimate the mean, mode, and credible intervals of the true conversion rate.
Visual Check: Trace Plots
While the numbers in the summary table are essential, visually inspecting the MCMC chains confirms the story.
Show the code
az.plot_trace(trace);
The trace plot above shows excellent convergence for our conversion rate (\(\theta\)) model, supporting the conclusions from our quantitative diagnostics. The plot is split into two panels 1. Right Panel: MCMC Sampling Behavior
This panel shows the raw sampled values across iterations for each of our four chains. The sampled values oscillate stably around ∼0.075 (7.5%) without any noticeable trends, sudden jumps, or long-term drifts.
The different lines (chains) are thoroughly intertwined and overlap completely. This “fuzzy caterpillar” appearance is the visual proof that the sampler is efficiently exploring the parameter space and that all chains have converged to the same distribution.
The stable behavior confirms the chain has reached stationarity, meaning it is now sampling from the true, converged Posterior distribution.
Left Panel: Posterior Distribution
This panel shows the estimated Posterior probability density function (PDF) based on the samples. The shape is smooth and unimodal (single peak), indicating a well-behaved posterior without ambiguity.
The peak is clearly centered at a value close to our observed rate (7.5%), which is what we expect when combining a prior (8%) and data (7.5%).
The spread of the distribution clearly visualizes our remaining uncertainty about the true conversion rate.
Prior Predictive Checks: Validating Model Assumptions
While we have demonstrated that the convergence of the fitted model a complete Bayesian analysis requires us to first validate the assumptions we made before seeing any data (priors). This validation is accomplished through the Prior Predictive Check.
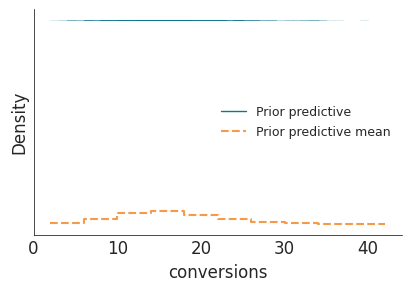
Prior Predictive Checks helps validate the prior assumptions before fitting the model to data. It show what kind of data the model expects to generate based solely on the prior beliefs.
Show the code
with pm.Model() as conversion_model:# Prior distribution based on historical performance conversion_rate = pm.Beta("conversion_rate", alpha=8, beta=92)# Likelihood function likelihood = pm.Binomial("observations", n=visitors, p=conversion_rate, observed=conversions)
Given our prior belief of an 8% conversion rate, we can simulate what kind of data we would expect to see if this belief were true. This is done by generating synthetic datasets from the prior distribution and comparing them to the actual observed data. This is acomplished in PyMC by running pm.sample_prior_predictive() function.
Show the code
with conversion_model: prior_pred = pm.sample_prior_predictive()
The generated plot from the prior predictive sampling shows the distributions of simulated data (the number of conversions) created by sampling from the \(\text{Beta}(8,92)\) prior distribution. - The distribution of the simulated data (prior predictive line) appear broadly spread out and relatively flat across a wide range (0 to 40+ conversions). This indicates that the prior allows for many different outcomes, and thus it is not overly restrictive. - The dashed line represents the average predicted number of conversions It is also quite flat and non-committal. - It evident that the prior predictive distribution does not overly concentrate around any specific number of conversions, which is desirable when we want to remain open to various possible outcomes. - So the prior predictive check confirms that our chosen Beta(8,92) prior is reasonable though it also quite weakly informative how?
Red flags to watch for:
Impossible values: Predictions outside the feasible range (e.g., negative conversion, >200 observations)
Unrealistic concentrations: If priors are too informative, you might see all predictions clustered in a narrow range
Poor scaling: Predictions that don’t match the scale of your problem
Posterior Predictive Checks
Posterior Predictive Checks addresses the important test: Does the model actually make sense given the data observed?
This moves the process from confirming the samplers or priors to validating the model itself.
PPCs evaluate model fit by comparing the observed data to simulated data from the posterior distribution. If a model accurately represents the data-generating process, the simulated data should resemble the actual observations.
To achive this it is important to generate new, simulated data from the posterior distribution and compare it to the actual observed data. This is done using the pm.sample_posterior_predictive function in PyMC.
Show the code
with pm.Model() as conversion_model:# Prior distribution based on historical performance conversion_rate = pm.Beta("conversion_rate", alpha=8, beta=92)# Likelihood function likelihood = pm.Binomial("observations", n=visitors, p=conversion_rate, observed=conversions)# Sample from posterior distribution trace = pm.sample(2000, tune=1000, chains=4, random_seed=42, return_inferencedata=True)with conversion_model: posterior_pred = pm.sample_posterior_predictive(trace, random_seed=42,)clear_output()
It clear that the predicted mean (15.314) is extremely close to the actual observed count (15). This is a strong indication that the conversion_rate model fits the data very well. And thus the choice of the Beta Prior and Binomial Likelihood is appropriate for this data. The model predicts that 95% of the time, the number of conversions will fall between 6 and 24. Since the company observed value of 15 falls well within this 95% HDI, the actual observation is considered highly plausible according to your model.
Show the code
ppc_samples = posterior_pred.posterior_predictive['observations'].values.flatten()percentile = (ppc_samples <= conversions).mean() *100print(f"Observed convervation ({conversions}) is at the {percentile:.1f}th percentile of predictions")
Observed convervation (15) is at the 53.7th percentile of predictions
The value of 53.7 is very close to the ideal 50, which provides further strong evidence (in addition to the mean of 15.314 already seen) that:
The model is not biased (it is not systematically over- or under-estimating the data).
The choice of the Beta-Binomial model is highly appropriate for this data set.
Model Utility and Business Decision
Following the confirmation of the reliability of the Bayesian model through the Posterior Predictive Check (PPC), the focus now shifts from “Does the model fit the data?” to the commercially critical question: “Is the model useful for making business decisions?”
Specifically, the derived posterior distribution is utilized to quantify the evidence that the new feature’s conversion rate (Feature B) is superior to the existing, established conversion rate (Feature A, which has a known baseline rate of 0.08).
To achieve this, we need to extract the posterior distribution for the conversion_rate parameter that your model estimated.
Next, calculate the “probability of superiority”—the probability that the new feature (B) is better than the old (A).
Finally, the expected uplift in conversion rate can be computed and translated into business value. This involves calculating the difference between the posterior mean conversion rate and the historical rate, then multiplying by the number of visitors and average revenue per conversion.
0.95: Strong Evidence. The new feature is very likely superior. Launching it should be considered.
0.80: Moderate Evidence. The new feature is likely better, but there is still a 20% chance it is worse. The decision depends on company risk tolerance.
0.50: No Evidence. The new feature is a toss-up; there is no statistical reason to prefer it over the old feature.
Show the code
prob_superiority = (conversion_samples > historical_baseline).mean()# Display the resultprint(f"The probability that the new feature is better than the old rate (0.08) is: {prob_superiority:.1%}")
The probability that the new feature is better than the old rate (0.08) is: 39.7%
The calculated Probability of Superiority is approximately 0.40, indicating that there is a 40% chance the new feature’s conversion rate is better than the old feature’s with 8% rate. This imply that there is a 60.3% chance the new feature is worse than the baseline.
Since the probability that the new feature is superior is well below the neutral benchmark of 50%, the data does not support replacing the existing Feature A with the new Feature B based on conversion rate alone. The new feature is highly likely to perform worse.
Probability of Meaningful Improvement.
Depending on the business context, one might also want to calculate the probability that the new feature is better by a meaningful margin (e.g., >1% improvement). This calculates the chance that the new feature is better than the old feature by a practically significant margin of at least 1 percentage point. This is a crucial business metric. Sometimes a tiny statistical “win” is not worth the cost of development and deployment. If this probability is low, it confirms the feature is not a major improvement.
Show the code
prob_1pct_improvement = (conversion_samples > historical_baseline+0.01).mean()print(f" Probability of >1% improvement: {prob_1pct_improvement:.1%}")
Probability of >1% improvement: 18.4%
Probability of Hitting a Target Rate
This calculates the chance that the true conversion rate of the new feature is 10% or higher. This is useful if 10% is a specific, ambitious KPI (Key Performance Indicator) or goal set by the marketing or product team. It tells how likely the team is to meet its goal.
Show the code
prob_10pct = (conversion_samples >0.10).mean()print(f" Probability of >10% improvement: {prob_10pct:.1%}")
Probability of >10% improvement: 6.3%
Expected Value of the Change.
This is the single-number best estimate of the average change (positive or negative) to expect upon deploying the new feature. This is the foundation for the “Expected Business Impact” section. If this value is negative, it represents an Expected Loss.
If one calculates: expected_uplift×Total Visitors×ARPC, the estimated dollar value of the change is obtained.
The goal is to translate the statistically determined average change in conversion rate into a clear financial outcome for the business. This calculation provides the most actionable insight for the go/no-go decision on the new feature.
Show the code
# Calculate key business probabilitiesexpected_uplift = conversion_samples.mean() - historical_baseline# Calculate expected business impactmonthly_visitors =10000expected_additional_conversions = monthly_visitors * expected_upliftconversion_value =50# Average value per conversionexpected_monthly_value = expected_additional_conversions * conversion_valueprint(f"Expected uplift: {expected_uplift:.3f} ({expected_uplift:.1%} points)")print(f"Expected monthly value: ${expected_monthly_value:,.0f}")
We see that the expected uplift is -0.030 (-3.0% points), indicating that, on average, the new feature is expected to decrease the conversion rate by 3 percentage points. The expected financial consequence of deploying the new feature is a loss of $1,717 per month
The data suggests that deploying the new feature would likely result in an Expected Monthly Loss of $1,717. This financial quantification is the most compelling reason to reject the new feature based on conversion rate performance.
The decision to proceed should only be considered if the feature provides other, unquantified benefits (e.g., improved customer retention, compliance, or brand value) that are estimated to be worth more than $1,717 per month.
Prior sensitivity analysis
Assessing how the choice of prior influences the final decision is important. This transparency is a key strength of Bayesian modeling, as it allows testing every assumption. Thus, one must determine how much the choice of prior affects the outcome by comparing several Beta priors. These comparisons will include priors from very optimistic (expecting a \(15\%\) conversion rate) to skeptical (expecting only \(4\%\)), plus an uninformative prior that lets the data speak entirely for itself.
domain = ["Very Optimistic", "Optimistic", "Historical Based", "Strong Historical", "Skeptical", "Uninformative"]reference_data = pd.DataFrame([ {'x': 0.08, 'label': 'Old Feature CR (8%)', 'color': 'red', 'label_x': 0.08}, {'x': 0.075, 'label': 'New Feature CR (7.5%)', 'color': 'green', 'label_x': 0.075}])chart = alt.Chart(traces_to_comprare).transform_density(density='Posterior', groupby=['Prior'], as_=['Posterior', 'density'])\ .mark_line(opacity=0.5)\ .encode(x='Posterior:Q', y='density:Q', color=alt.Color("Prior:N").scale(domain=domain, range=colors[:len(domain)]) )reference_lines = alt.Chart(reference_data).mark_rule( strokeDash=[5, 5], # Dashed line size=1, ).encode( x='x:Q', color=alt.Color('label:N', scale=alt.Scale(domain=reference_data['label'].tolist(), range=reference_data['color'].tolist()), legend=alt.Legend(title="Conversion Rate")))final=chart + reference_lines final=final.properties(title='Posterior Distributions by Prior Belief', width=700, height=200).configure_axis(# Set grid to False to remove all grid lines grid=False).configure_view(# Optional: Remove the surrounding border of the plot area strokeWidth=0)final.save('posterior_sensitivity.pdf')final
The figure above show Posterior belief distributions under different prior assumptions. Each curve in the figure represents a posterior distribution for the conversion rate under a different prior assumption. The horizontal axis shows possible conversion rates, and the vertical axis shows how plausible each value is after combining the prior belief with the observed data.
Despite very different starting assumptions, the posterior estimates converge around 7–10%, showing that the data provide a stable, consistent signal largely independent of the chosen prior. All reasonable priors converge to the same conclusion: the new feature likely isn’t better than the old one.
To support decision-making, we compile a summary table comparing key metrics across these prior choices.
How Different Starting Assumptions Affect Final Conclusions
Prior Belief
Prior Distribution
Prior Mean
Posterior Mean
Prob. Better
Expected Uplift
Expected Monthly Value
Uncertainty Reduction
Data Influence
Very Optimistic
Beta(15, 85)
0.150
0.100
88.2%
$2.0%
$9,930
52.2%
Moderate
Optimistic
Beta(12, 88)
0.120
0.090
71.0%
$1.0%
$4,992
49.1%
Moderate
Historical Based
Beta(8, 92)
0.080
0.077
39.7%
$-0.3%
$-1,717
44.1%
Moderate
Strong Historical
Beta(80, 920)
0.080
0.079
47.3%
$-0.1%
$-263
10.4%
Moderate
Skeptical
Beta(4, 96)
0.040
0.064
11.8%
$-1.6%
$-8,231
29.0%
Moderate
Uninformative
Beta(1, 1)
0.500
0.079
44.8%
$-0.1%
$-456
93.5%
Strong
Analysis shows robustness of conclusions to different prior assumptions • Even skeptical priors converge toward data-driven truth
Key observations:
Prior Pull: The data moderate extreme beliefs. The very optimistic prior (0.150) is pulled down to 0.100, while the skeptical prior (0.040) rises to 0.064—demonstrating how new evidence shifts expectations toward a central value.
Prior Strength vs. Data Influence: The Strong Historical prior (Beta(80, 920)) and Uninformative prior (Beta(1, 1)) yield similar posteriors (~0.079, ~45% Prob_Better), but for opposite reasons. The former is dominated by prior belief; the latter, by data—showing that strong evidence can overcome weak or missing priors.
Impact on Decision Metrics:: The Very Optimistic prior suggests an 88% Prob_Better and +$9.9k expected value, favoring a launch. The Skeptical prior predicts only 12% Prob_Better and –$8.2k, suggesting the opposite. Even moderate priors (e.g., 40–47%) could tip a go/no-go decision depending on the threshold.
Common bayesian pitfalls and best practices
While Bayesian modeling provides a powerful framework for decision-making under uncertainty, several common mistakes can reduce its effectiveness.
The first is overconfident priors, where excessively strong prior assumptions prevent new data from influencing the results. This issue is best mitigated by starting with weak or moderately informative priors and refining them as more evidence becomes available.
A second pitfall is ignoring prior sensitivity. Conclusions may shift significantly depending on the chosen prior distribution, so it is essential to conduct sensitivity analyses using multiple plausible priors to ensure that insights are robust.
The third major issue involves misinterpreting probability. A statement such as “95% probability” does not imply absolute certainty; rather, it reflects the degree of belief given the available data and assumptions. Probabilities in Bayesian analysis are best interpreted in terms of relative confidence, risk, and decision trade-offs.
Next steps in the bayesian journey
We have laid the groundwork by exploring the core components of the Bayesian approach. The subsequent session will focus on advanced practical implementation. We will apply this framework to critical survival analysis problems, modeling the probability and timing of events such as equipment failure.